Introduction
In this post, we will explore the concept of algorithm efficiency and how to measure this efficiency using big O notation. Additionally, we will see how this can help us write more performance code. Big O notation allows us to evaluate the performance of an algorithm according to the size of its data set.
What is big O notation and algorithm efficiency?
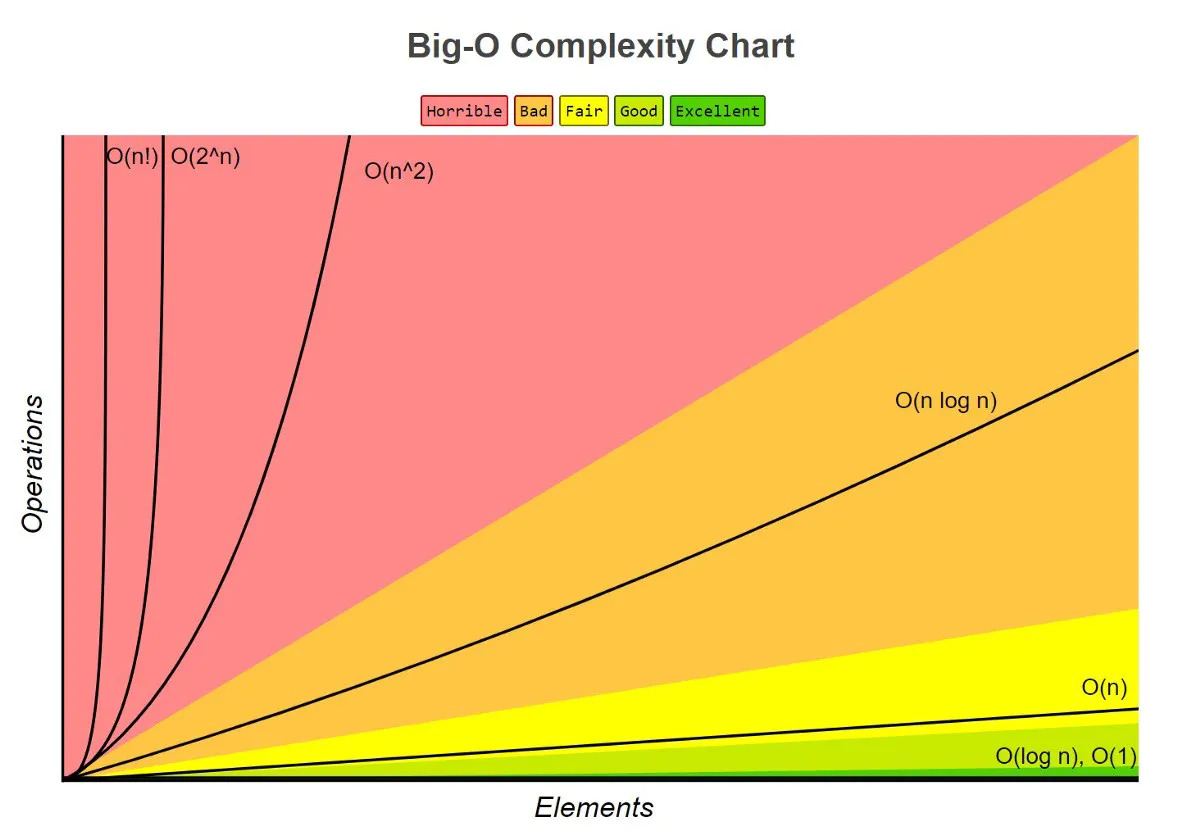
Algorithm efficiency is the ability to solve a problem in a reasonable time and with efficient use of computational resources such as processing and memory. Big O notation is a way of measuring the efficiency of an algorithm, describing the asymptotic behavior of a function. This means that we can evaluate the rate of growth of the function, comparing it to other algorithms.
Big O notation is represented by the letter O and is used as follows: Θ(f(n)), where f(n) is the measure by which the size of the input (n) increases. For example, an algorithm that grows quadratically, that is, increases proportionally to the square of each additional input, is represented by Θ(n²).
- Constant time: Θ(1)
- Linear time: Θ(n)
- Logarithmic time: Θ(log(n))
- Quadratic time: Θ(n²)
Big O notation in code
Suppose you have a list and need to find a certain element ‘x’. This algorithm is called sequential search.
Another example is when you need to sort a list. This algorithm is called insertion sort.
Sequential search example
// linear time
function sequentialSearch(arr: number[], x: number) {
for (let i = 0; i < arr.length; i++) {
if (arr[i] === x) {
return i
}
}
return -1
}Insertion sort example
// quadratic time
function insertionSort(arr: number[]) {
for (let i = 1; i < arr.length; i++) {
let currentVal = arr[i]
for (var j = i - 1; j >= 0 && arr[j] > currentVal; j--) {
arr[j + 1] = arr[j]
}
arr[j + 1] = currentVal
console.log(arr)
}
return arr
}Both codes work and solve the proposed problem, but one is more performative than the other. The first code is linear, which means that the for loop will be executed a number of times directly proportional to the size of the array. This means that if the array has n elements, the loop will be executed n times, which can be represented by Θ(n).
The advantage of this approach is that, in case of larger arrays, the code will run faster, as the number of iterations is proportional to the size of the array. This makes the time complexity of the code limited by the size of the array, resulting in a less steep growth chart compared to a code with quadratic complexity. In other words, the first code is more performative and efficient in situations where the array can be very large.
The second code is an example of quadratic complexity Θ(n²). This means that the for loop inside the for loop will be executed a number of times proportional to the square of the size of the array. In other words, if the array has n elements, the inner loop will be executed n * n times, which can be represented by Θ(n²).
The implications of this complexity are that, in larger arrays, the growth chart will be steeper, resulting in slower and more complex code as the input gets larger.
Now, let’s see some examples of code with logarithmic complexities O(log(n)) and O(n log(n)).
Suppose you receive a list of numbers and need to find a certain number x in the list. To do this, you can use the binary search algorithm, which has complexity O(log(n)).
Another example is when you need to sort a list of numbers in a logarithmic way. To do this, you can use the merge sort algorithm, which has complexity O(n log(n)).
These algorithms are more performative and efficient than linear or quadratic approaches in situations where the size of the input can be very large.
Binary search example
// O(log(n))
function binarySearch(arr: number[], x: number) {
let left = 0
let right = arr.length - 1
while (left <= right) {
let mid = Math.floor((left + right) / 2)
if (arr[mid] === x) {
return mid
}
if (arr[mid] < x) {
left = mid + 1
} else {
right = mid - 1
}
}
return -1
}Merge sort example
// O(n log(n))
function mergeSort(arr: number[]) {
if (arr.length === 1) {
return arr
}
let mid = Math.floor(arr.length / 2)
let left = arr.slice(0, mid)
let right = arr.slice(mid)
return merge(mergeSort(left), mergeSort(right))
}
function merge(left: number[], right: number[]) {
let result = []
let i = 0
let j = 0
while (i < left.length && j < right.length) {
if (left[i] < right[j]) {
result.push(left[i])
i++
} else {
result.push(right[j])
j++
}
}
return result.concat(left.slice(i)).concat(right.slice(j))
}Both examples are valid, but they have different time complexities. The first one is O(log(n)), which means that the running time increases logarithmically with respect to the size of the input. In other words, in the worst case, if the array has 8 elements, the algorithm will be executed 3 times. For example: log2(8) = 3.
The second example, O(n log(n)), is a notation that indicates that the running time of an algorithm increases proportionally to the product of the size of the input data and the logarithm of that size. This means that, in the worst case, if the array has 8 elements, the algorithm will be executed 24 times. For example: 8 * log2(8) = 24.
However, it is important to remember that the temporal complexity of an algorithm does not necessarily imply higher or lower speed. It is possible that an algorithm with worse complexity is faster than an algorithm with better complexity, depending on the specific input. However, in general, it is safe to say that the lower the complexity, the faster the algorithm will be, as the input increases.
For those who want to delve deeper into the subject, I recommend reading the book “Introduction to Algorithms” by Thomas H. Cormen.