Introduction
A parser can have various applications in everyday life, and you probably use some parser daily. Babel, webpack, eslint, prettier, and jscodeshift. All of them, behind the scenes, run a parser that manipulates an Abstract Syntax Tree (AST) to do what you need - we’ll talk about that later, don’t worry.
The idea of this text is to introduce the concept of lexing and parsing, implementing them using JavaScript to analyze expressions in JSON. The goal will be to separate this process into functions, explain these functions, and, in the end, have you implement a JSON parser generating an AST.
It’s worth noting that my repository is open, and you can access it here.
Lexing
A lexer will be responsible for converting an expression, whatever it may be, into tokens. These tokens are identifiable elements that have an assigned meaning.
You can divide these tokens in several ways, such as identifier, keyword, delimiter, operator, literal, and comment.
{ "type": "LEFT_BRACE", "value": undefined } is an example of a delimiter. { "type": "STRING", "value": "name" } is an example of a literal.
Example: {"name":"Vitor","age":18}
[
{ "type": "LEFT_BRACE", "value": undefined },
{ "type": "STRING", "value": "name" },
{ "type": "COLON", "value": undefined },
{ "type": "STRING", "value": "Vitor" },
{ "type": "COMMA", "value": undefined },
{ "type": "STRING", "value": "age" },
{ "type": "COLON", "value": undefined },
{ "type": "NUMBER", "value": "18" },
{ "type": "RIGHT_BRACE", "value": undefined }
]Note that in lexical analysis, you separate your expression into tokens, and each token has its identification.
To code this, let’s first understand what we will be doing exactly. The idea of the lexer function is to receive an argument of type String and return an Array of tokens, which will be our JSON divided into specific types of information, as we have already seen and discussed.
To achieve this, we will create a variable called current, which will store the current position of the character in the input being analyzed by the lexer. In other words, it represents the position it is currently at in our JSON. Additionally, we will have a constant called tokens, which will be an array that will hold all of our tokens in the end.
export const lexer = (input: string): Token[] => {
let current = 0;
const tokens: Token:[] = [];
}Now, we need to run a loop that will iterate until all the characters of the input have been processed.
Note that it’s possible to refactor all these
ifblocks into aswitchstatement. However, I followed an imperative style.
export const lexer = (input: string): Token[] => {
let current = 0
const tokens: Token[] = []
while (current < input.length) {
let char = input[current]
if (char === '{') {
tokens.push(createToken(TOKEN_TYPES.LEFT_BRACE))
current++
continue
}
if (char === '}') {
tokens.push(createToken(TOKEN_TYPES.RIGHT_BRACE))
current++
continue
}
if (char === '[') {
tokens.push(createToken(TOKEN_TYPES.LEFT_BRACKET))
current++
continue
}
if (char === ']') {
tokens.push(createToken(TOKEN_TYPES.RIGHT_BRACKET))
current++
continue
}
if (char === ':') {
tokens.push(createToken(TOKEN_TYPES.COLON))
current++
continue
}
if (char === ',') {
tokens.push(createToken(TOKEN_TYPES.COMMA))
current++
continue
}
const WHITESPACE = /\s/
if (WHITESPACE.test(char)) {
current++
continue
}
const NUMBERS = /[0-9]/
if (NUMBERS.test(char)) {
let value = ''
while (NUMBERS.test(char)) {
value += char
char = input[++current]
}
tokens.push(createToken(TOKEN_TYPES.NUMBER, value))
continue
}
if (char === '"') {
let value = ''
char = input[++current]
while (char !== '"') {
value += char
char = input[++current]
}
char = input[++current]
tokens.push(createToken(TOKEN_TYPES.STRING, value))
continue
}
if (
char === 't' &&
input[current + 1] === 'r' &&
input[current + 2] === 'u' &&
input[current + 3] === 'e'
) {
tokens.push(createToken(TOKEN_TYPES.TRUE))
current += 4
continue
}
if (
char === 'f' &&
input[current + 1] === 'a' &&
input[current + 2] === 'l' &&
input[current + 3] === 's' &&
input[current + 4] === 'e'
) {
tokens.push(createToken(TOKEN_TYPES.FALSE))
current += 5
continue
}
if (
char === 'n' &&
input[current + 1] === 'u' &&
input[current + 2] === 'l' &&
input[current + 3] === 'l'
) {
tokens.push(createToken(TOKEN_TYPES.NULL))
current += 4
continue
}
throw new TypeError('I dont know what this character is: ' + char)
}
return tokens
}This code may seem complicated, but it’s actually quite simple. Inside my loop, I start by defining the variable char, which will store the character currently being analyzed in that iteration of the loop. Then, for each type of character, we want a specific action.
If the char is equal to {, we push into the tokens array, passing to it the ENUM of Tokens, which will be the name of each token.
export enum TOKEN_TYPES {
LEFT_BRACE = 'LEFT_BRACE',
RIGHT_BRACE = 'RIGHT_BRACE',
LEFT_BRACKET = 'LEFT_BRACKET',
RIGHT_BRACKET = 'RIGHT_BRACKET',
COLON = 'COLON',
COMMA = 'COMMA',
STRING = 'STRING',
NUMBER = 'NUMBER',
TRUE = 'TRUE',
FALSE = 'FALSE',
NULL = 'NULL',
}In the function createToken, it only returns an object with the type or value if it exists.
export const createToken = (type: TOKEN_TYPES, value?: string): Token => {
return {
type,
value,
}
}After that, it increments +1 to the current variable to move to the next char in our string. This process is quite repetitive and straightforward. I won’t explain each one of them, but it’s worth paying attention to those that deviate a bit from the pattern.
if (char === '"') {
let value = ''
char = input[++current]
while (char !== '"') {
value += char
char = input[++current]
}
char = input[++current]
tokens.push(createToken(TOKEN_TYPES.STRING, value))
continue
}
if (
char === 't' &&
input[current + 1] === 'r' &&
input[current + 2] === 'u' &&
input[current + 3] === 'e'
) {
tokens.push(createToken(TOKEN_TYPES.TRUE))
current += 4
continue
}
if (
char === 'f' &&
input[current + 1] === 'a' &&
input[current + 2] === 'l' &&
input[current + 3] === 's' &&
input[current + 4] === 'e'
) {
tokens.push(createToken(TOKEN_TYPES.FALSE))
current += 5
continue
}
if (
char === 'n' &&
input[current + 1] === 'u' &&
input[current + 2] === 'l' &&
input[current + 3] === 'l'
) {
tokens.push(createToken(TOKEN_TYPES.NULL))
current += 4
continue
}If the char is equal to ", we enter a loop to continue reading the subsequent characters until we find another quotation mark, as this indicates the end of the string. All the characters read during this loop are concatenated into the “value” variable. Then, a new token is added to the “tokens” array.
The other lines are used to set boolean values. If the current character is “f” and the subsequent characters form the word false, we add false to the tokens array. The same process is repeated for true.
In all cases, the current variable is incremented to point to the next character to be processed, just like we did throughout the rest of our code.
Parsing
A parser is responsible for transforming a sequence of tokens into a data structure, in this case, an AST.
Illustration of an AST taken from the book “Modern Compiler Implementation in ML.”
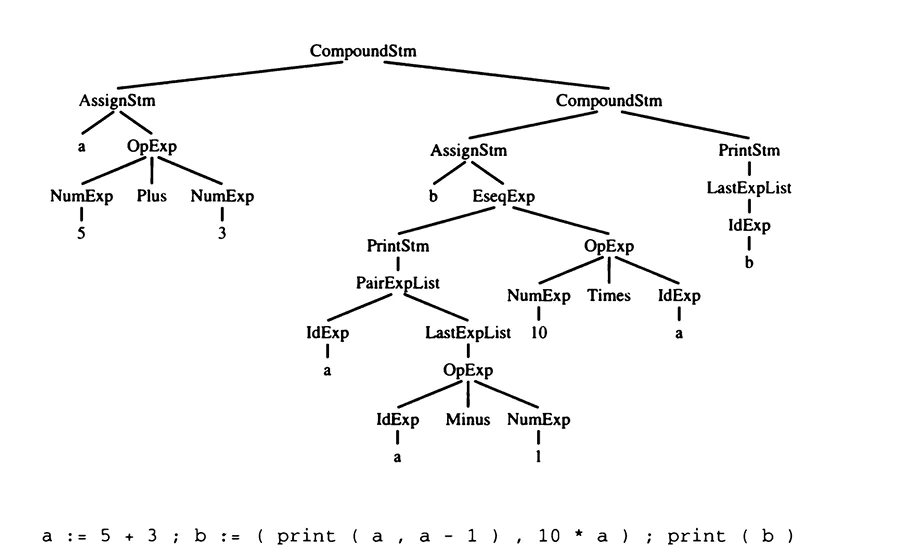
An Abstract Syntax Tree (AST) is a data structure that represents the syntactic structure of a program. Within the AST, there are several nodes, and each node represents a valid syntactic construct of the program. For example:
parser: {
"type": "Program",
"body": [
{
"type": "ObjectExpression",
"properties": [
{
"type": "Property",
"key": {
"type": "STRING",
"value": "name"
},
"value": {
"type": "StringLiteral",
"value": "Vitor"
}
},
{
"type": "Property",
"key": {
"type": "STRING",
"value": "age"
},
"value": {
"type": "NumberLiteral",
"value": "18"
}
}
]
}
]
}This is the AST of the JSON I exemplified at the beginning. In this example, we have a total of 8 nodes. The Program node represents the main program. ObjectExpression represents an object, Property represents a property within an object, consisting of a key and a value. STRING represents a string used as a key, StringLiteral represents a string within a property, and NumberLiteral represents a numeric value within a property.
Through an AST, it’s possible to optimize code, transform one code into another, perform static analysis, generate code, and more. For example, you could implement a new syntax, create a parser, and generate JavaScript code that would execute normally.
To generate our AST, we will need a function that receives our array of tokens, iterates through it, and generates the AST according to the tokens it encounters. For this purpose, we will create a function called walk, which will traverse the tokens and return the nodes of the AST.
export const parser = (tokens: Array<{ type: string; value?: any }>) => {
let current = 0;
const walk = () => {
let token = tokens[current];
if (token.type === TOKEN_TYPES.LEFT_BRACE) {
token = tokens[++current];
const node: {
type: string;
properties?: Array<{ type: string; key: any; value: any }>;
} = {
type: 'ObjectExpression',
properties: [],
};
while (token.type !== TOKEN_TYPES.RIGHT_BRACE) {
const property: { type: string; key: any; value: any } = {
type: 'Property',
key: token,
value: null,
};
token = tokens[++current];
token = tokens[++current];
property.value = walk();
node.properties.push(property);
token = tokens[current];
if (token.type === TOKEN_TYPES.COMMA) {
token = tokens[++current];
}
}
current++;
return node;
}The first check we perform is whether the current token is {. If it is, we create a new node of type ObjectExpression and iterate through the following tokens, adding them as properties of the object until we find the end of the key, which is }. Each property is represented by a node of type Property. This Property type has a value that is generated by the walk() function, which is called recursively.
Note that I use tokens[++current]. This is to advance the cursor to the next token. And if a token of type , (comma) is found, we advance the cursor again to skip the comma.
The rest of the code is quite similar to what I’ve just explained, so it’s worth the effort to look and try to understand or implement the rest on your own. It’s not very complex.
Finally, I create the constant ast, which will contain the type Program and the body of the AST, generated by the walk() function. The while loop ensures that current does not exceed the size of the tokens array.
After that, we simply return the AST.
export const parser = (tokens: Array<{ type: string; value?: any }>) => {
let current = 0
const walk = () => {
let token = tokens[current]
if (token.type === TOKEN_TYPES.LEFT_BRACE) {
token = tokens[++current]
const node: {
type: string
properties?: Array<{ type: string; key: any; value: any }>
} = {
type: 'ObjectExpression',
properties: [],
}
while (token.type !== TOKEN_TYPES.RIGHT_BRACE) {
const property: { type: string; key: any; value: any } = {
type: 'Property',
key: token,
value: null,
}
token = tokens[++current]
token = tokens[++current]
property.value = walk()
node.properties.push(property)
token = tokens[current]
if (token.type === TOKEN_TYPES.COMMA) {
token = tokens[++current]
}
}
current++
return node
}
if (token.type === TOKEN_TYPES.RIGHT_BRACE) {
current++
return {
type: 'ObjectExpression',
properties: [],
}
}
if (token.type === TOKEN_TYPES.LEFT_BRACKET) {
token = tokens[++current]
const node: {
type: string
elements?: Array<{ type?: string; value?: any }>
} = {
type: 'ArrayExpression',
elements: [],
}
while (token.type !== TOKEN_TYPES.RIGHT_BRACKET) {
node.elements.push(walk())
token = tokens[current]
if (token.type === TOKEN_TYPES.COMMA) {
token = tokens[++current]
}
}
current++
return node
}
if (token.type === TOKEN_TYPES.STRING) {
current++
return {
type: 'StringLiteral',
value: token.value,
}
}
if (token.type === TOKEN_TYPES.NUMBER) {
current++
return {
type: 'NumberLiteral',
value: token.value,
}
}
if (token.type === TOKEN_TYPES.TRUE) {
current++
return {
type: 'BooleanLiteral',
value: true,
}
}
if (token.type === TOKEN_TYPES.FALSE) {
current++
return {
type: 'BooleanLiteral',
value: false,
}
}
if (token.type === TOKEN_TYPES.NULL) {
current++
return {
type: 'NullLiteral',
value: null,
}
}
throw new TypeError(token.type)
}
const ast = {
type: 'Program',
body: [],
}
while (current < tokens.length) {
ast.body.push(walk())
}
return ast
}const tokens = lexer('{"name":"Vitor","age":18}')
console.log('tokens', tokens)
const json = parser(tokens)
console.log('parser:', JSON.stringify(json, null, 2))Parsing can be fun, but in reality, it’s not often written, and you probably don’t need to write your own parser. If you are implementing a programming language, for example, there are already various tools that can do this job for you, such as OCamllex, Menhir, or Nearley.
It’s also essential to note that, as this is an introductory article, I didn’t cover the different tokenization and parsing techniques, such as LR(0), LR(1), SLR(1), etc. However, be aware that these techniques exist, and you can research more about them. There are also many books that cover these topics.
If you want to see how the AST of popular languages looks, I recommend the AST Explorer. It supports various languages, and you can view the complete AST and navigate through the nodes. If you want to go further, you can try to copy some logic from an existing parser and implement it in your own, such as calculating an expression according to precedence order, for example: 1 + 2 * 3 (which is 7, not 9).
If you’re interested in learning more, I recommend the book “Modern Compiler Implementation in ML.” Despite the title being in ML, you can study from it without necessarily writing ML code, as there are other versions written in C, C++, and Java.